Tag: perf
-
Pipeline Speak: Learning More About Intel Microarchitechture Codename Sandy Bridge 中文翻譯
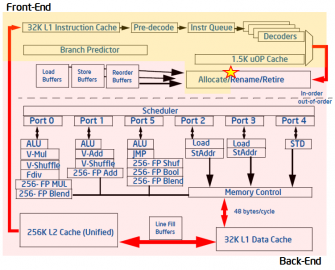
中文翻譯前言 為了理解 perf 的輸出意義[1],必須要了解 CPU Microarchitecture。如果你用 perf stat -d gzip file1 這個方式來輸出,你會發現到輸出中有加粗這個部份: ➜ /tmp perf stat -d gzip files Performance counter stats for ‘gzip files’: 6990.942695 task-clock:u (msec) # 0.996 CPUs utilized 0 context-switches:u # 0.000 K/sec 0 cpu-migrations:u # 0.000 K/sec 112 page-faults:u # 0.016 K/sec 22,653,310,816 cycles:u # 3.240 GHz (33.32%) 9,561,514,420 stalled-cycles-frontend:u #…