Tag: Intel
-

Pipeline Speak, Part 2: The Second Part of the Sandy Bridge Pipeline 中文翻譯
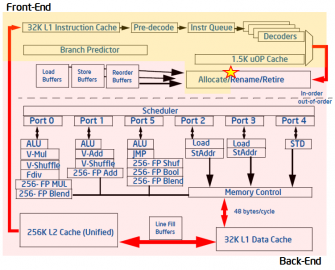
原文:https://software.intel.com/en-us/blogs/2011/12/01/pipeline-speak-part-2-the-second-part-of-the-sandy-bridge-pipeline 管線後端 The Back-End 管線的後端負責執行從前端產生的微指令。為了要讓後端的資源能夠有效的被利用,後端使用自己的 bookkeeping system 來追蹤每一個微指令,其所需資料 [data requires] 以及執行狀態 [exectes status]。然後它將以任何順序來執行微指令 ─ 根據微指令的所需資料什麼時候全部準備完成以及是否有可用的執行資源。微指令的 bookkeeping 以及排程可以說非常的複雜,而且需要許多專用的隊列結構。當有些隊列結構已經滿了,也就是後端不能在從前端接收新的微指令 ─ 在 Sandy Bridge 最佳化方法中,我們稱這種情況做 ” back-end bound pipeline slots”。 後端持續在追蹤的執行資源 [ execution resources] 稱做執行單元 [execution units]。每個 microarchitecture 可能會有稍微不同的 Layout 以及不同的可用執行單元。這些執行單元是在處理上處理特定功能的邏輯組件,像是加法、除法、邏輯位移、從記憶體讀取等。當微指令使用完執行單元以及所有資料都已經讀取或儲存完畢,我們稱他們已經 “退休” [retired] ─ 這表示微指令已經完成在管線該做的工作。這些微指令絕對不會再被顯式的被轉換回指令 [instructions]。而一個指令被 “退休” 則代表所有的其產生的微指令都已經 “退休”,不過這只是個抽象化的表達方式來說明管線後端是如何處理微指令而已。 了解一點處理器的微架構,包括管線的基礎知識,在效能分析上可以說非常的有幫助。特別是在 Intel Sandy Birdge 架構,因為,第一次在 x86 處理器上,performance events 可以從一個內聚的方法…
-
Pipeline Speak: Learning More About Intel Microarchitechture Codename Sandy Bridge 中文翻譯
中文翻譯前言 為了理解 perf 的輸出意義[1],必須要了解 CPU Microarchitecture。如果你用 perf stat -d gzip file1 這個方式來輸出,你會發現到輸出中有加粗這個部份: ➜ /tmp perf stat -d gzip files Performance counter stats for ‘gzip files’: 6990.942695 task-clock:u (msec) # 0.996 CPUs utilized 0 context-switches:u # 0.000 K/sec 0 cpu-migrations:u # 0.000 K/sec 112 page-faults:u # 0.016 K/sec 22,653,310,816 cycles:u # 3.240 GHz (33.32%) 9,561,514,420 stalled-cycles-frontend:u #…