concurrent.futures – Launching parallel tasks
The
concurrent.futuresmodule provides a high-level interface for asynchronously executing callables.
官方介紹文件:17.4. concurrent.futures — Launching parallel tasks
concurrent.futures 提供了一組高階 API 給使用者操作非同步執行的任務。透過 ThreadPoolExectuor 執行 thread 層級的非同步任務,或是使用 ProcessPoolExecutor 執行 process 層級的非同步任務。兩者的 API 介面都相同,同樣繼承於 Executor。
01. Quickstart Tutorial
第一個範例的 target function 使用大家最喜歡的遞迴費氏數列:
|
1 2 3 4 |
def fib(n): if n < 2: return 1 return fib(n – 1) + fib(n – 2) |
首先,最簡單的方式,使用 submit來給予任務:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# fib_submit.py import concurrent.futures def fib(n): if n < 2: return 1 return fib(n – 1) + fib(n – 2) with concurrent.futures.ProcessPoolExecutor() as executor: s1 = executor.submit(fib, 10) # Return future object s2 = executor.submit(fib, 20) s3 = executor.submit(fib, 5) s4 = executor.submit(fib, 8) print(s1.result()) print(s2.result()) print(s3.result()) print(s4.result()) |
輸出結果:
|
1 2 3 4 5 |
➜ cpython git:(master) ✗ ./python.exe fib_submit.py 89 10946 8 34 |
接著我們使用 ProcessPoolExecutor 的 map 來計算多組費氏數列的數字 (記得!使用 with statement 才是蛇族的良好習慣):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# fib_process_map import concurrent.futures FIBS = [28, 10, 20, 20, 23, 30, 10, 30] def fib(n): if n < 2: return 1 return fib(n – 1) + fib(n – 2) def process(): with concurrent.futures.ProcessPoolExecutor() as executor: for number, fib_value in zip(FIBS, executor.map(fib, FIBS)): print(“%d’s fib number is %d” % (number, fib_value)) if __name__ == ‘__main__’: process() |
輸出結果:
|
1 2 3 4 5 6 7 8 9 |
➜ cpython git:(master) ✗ ./python.exe fib_process_map.py 28‘s fib number is 514229 10′s fib number is 89 20‘s fib number is 10946 20′s fib number is 10946 23‘s fib number is 46368 30′s fib number is 1346269 10‘s fib number is 89 30′s fib number is 1346269 |
接著我們透過 ThreadPoolExecutor 的 submit 來爬蟲 (務必記得,使用 with statement 才能保平安):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
# web_scrap.py import concurrent.futures import requests # This is not standard library URLS = [ ‘https://docs.python.org/3/library/ast.html’, ‘https://docs.python.org/3/library/abc.html’, ‘https://docs.python.org/3/library/time.html’, ‘https://docs.python.org/3/library/os.html’, ‘https://docs.python.org/3/library/sys.html’, ‘https://docs.python.org/3/library/io.html’, ‘https://docs.python.org/3/library/pdb.html’, ‘https://docs.python.org/3/library/weakref.html’ ] def get_content(url): return requests.get(url).text def scrap(): with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor: future_to_url = {executor.submit(get_content, url): url for url in URLS} for future in concurrent.futures.as_completed(future_to_url): url = future_to_url[future] try: data = future.result() except Execption as exc: print(‘%r generated an exception: %s’ % (url, exc)) else: print(‘%r page length is %d’ % (url, len(data))) def main(): for url in URLS: try: data = get_content(url) except Exception as exc: print(‘%r generated an exception: %s’ % (url, exc)) else: print(‘%r page length is %d’ % (url, len(data))) if __name__ == ‘__main__’: scrap() |
使用最潮的 perf 來看效能差異 (這是 Python 的 perf 套件,不是 Linux kernel 的那個):
|
1 2 3 4 5 |
➜ cpython git:(master) ✗ python3 –m perf timeit ‘from web_scrap import scrap;scrap()’ ..................... Mean +– std dev: 1.03 sec +– 0.10 sec ➜ cpython git:(master) ✗ python3 –m perf timeit ‘from web_scrap import main;main()’ Mean +– std dev: 4.07 sec +– 0.48 sec |
效果十分顯著!比起一個一個抓,使用 ThreadPoolExecutor 快了 4 倍速的時間。還不快把所有程式碼拿出來改寫!
02. HOW-TO Guides
Executor 改變 max_workers 來加速
ThreadPoolExecutor 以及 ProcessPoolExecutor 都可以在建立時改變 max_workers 參數來調整 worker 的數量。如果 max_workers 小於等於 0 會產生 ValueError。預設的 worker 數量為 CPU 數量 * 5。
|
1 2 3 4 5 6 7 8 9 10 |
with concurrent.futures.ProcessPoolExecutor(max_workers=1) as executor: results = executor.map(int, [‘1’, ‘2’, ‘3’, ‘4’, ‘5’]) for v in results: print(v) with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor: results = executor.map(requests.get, [‘https://google.com’] * 10) for r in results: print(len(r.text)) |
ProcessPoolExecutor.map()改變 chunksize 來加速
使用 Proc essPoolExecutor.map()的時候,可以透過改變 chunksize 來加速,預設的 chunksize 是 1,所以如果遇到一些高 CPU-bound 但低執行時間的任務時,可以改變 chunksize 來進行加速,舉例同樣採用費氏數列,但是這次要計算很多很多的小數字:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# fib_process_chunksize.py import concurrent.futures FIBS = [5, 5, 5, 5, 5, 10, 10, 10, 10] * 50 def fib(n): if n < 2: return 1 return fib(n – 1) + fib(n – 2) def process(chunksize=1): with concurrent.futures.ProcessPoolExecutor() as executor: for number, fib_value in zip(FIBS, executor.map(fib, FIBS, chunksize=chunksize)): s = “%d’s fib number is %d” % (number, fib_value) def main(): for num in FIBS: s = “%d’s fib number is %d” % (num, fib(num)) if __name__ == ‘__main__’: process() |
我們使用最夯的 perf 套件來計算執行時間:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
➜ cpython git:(master) ✗ python3 –m perf timeit ‘from tests import process;process(1)’ # Chunk size = 1 ..................... Mean +– std dev: 280 ms +– 91 ms ➜ cpython git:(master) ✗ python3 –m perf timeit ‘from tests import process;process(8)’ # Chunk size = 8 ..................... Mean +– std dev: 43.5 ms +– 4.0 ms ➜ cpython git:(master) ✗ python3 –m perf timeit ‘from tests import process;process(16)’ ..................... Mean +– std dev: 33.5 ms +– 5.9 ms ➜ cpython git:(master) ✗ python3 –m perf timeit ‘from tests import process;process(32)’ ..................... Mean +– std dev: 28.8 ms +– 4.5 ms ➜ cpython git:(master) ✗ python3 –m perf timeit ‘from tests import main;main()’ ..................... Mean +– std dev: 10.1 ms +– 2.8 ms |
實驗輸出有將輸出的部分警告 (maximum > mean, standard deviation too large…etc) 給移除。可以看到改變 chunksize 對於執行時間有著巨大的改變。最後一組資料是線性執行,在這邊比起使用 ProcessPool 還要來得快很多 (why? see below discussion)。
03. Discussions
> 什麼時候使用 ThreadPoolExecutor ,什麼時候選用 ProcessPoolExecutor
關於這個問題,我們必須先來了解,Thread 以及 Process 有什麼差別。使用 Thread 可以認為是 Concurrency,而 Process 則可以當成 Parallelism。兩者有什麼差別呢,用圖來說明 (圖片出處:Concurrency is not parallelism):
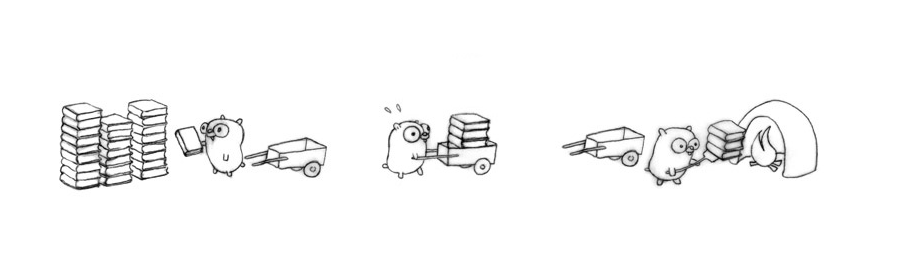
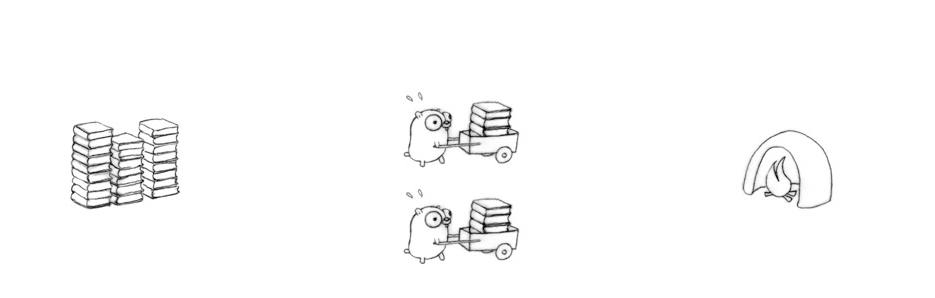
Thread 會在同一個 Process 裡面做事,遇到被 I/O waiting hang-up 的時候 (例如 waiting for socket response),會由另外一個 Thread 繼續做事。當任務有很多 I/O 的動作時,就適合使用 ThreadPoolExecutor。
Process 則是會開新的 Process 來處理,因此對於高 CPU 計算的工作帶來效益,不同於 socket 的狀況,這些計算並不會把自身 hang-up,而會持續不斷的計算。例如說費氏數列的計算就是這樣。對於這種狀況,使用 Process 就如同開影分身,能夠讓整體的計算更快完成。這時候就適合使用 ProcessPoolExecutor。
> 前面的範例裡面,費氏數列計算使用 ProcessPoolExecutor 還變得更慢,你來騙錢的齁~
這是因為,開 thread 還有開 process 都會有成本,這些成本如果沒有辦法平均攤銷到計算裡面的話,就會變成阻力強大 overhead。從前面的例子可以看到,如果在 ProcessPoolExecutor 使用 chunksize = 1 的狀況下,為了一個簡單的費氏數列計算就要開一個新的 Process,而且算完一個就把 process 關掉,這樣就會產生大量的 overhead,讓計算時間暴衝為 linear 的 28 倍。我們可以透過將 chunksize 改成 50 來攤銷掉 overhead,讓一個 process 一次計算 50 個數字再把自己結束掉。
因此,不是開很多 Process 就會變很快,對於 overhead 還是要自己體會一遍的。
作業:透過 perf 理解 Process / Thread PoolExecutor 對於任務的效能影響。
> 為什麼不使用 multiprocessing 就好?
相較於 multiprocessing,concurrent.futures 提供了一組更高階,且 API 介面相同的兩個 executor,同時有著簡單的用法 (submit or map),使用者如果不關心非同步執行細項的事情 (例如 barrier,lock 之類的 synchronize detail),使用 concurrent.futures 即可。
04. Implementation Coding Tips
|
1 2 3 4 5 6 7 |
import itertools _counter = itertools.count().__next__ print(‘id: %d’ % (_counter()) print(‘id: %d’ % (_counter()) print(‘id: %d’ % (_counter()) |
05. References
- Concurrency is not parallelism
- 17.4. concurrent.futures — Launching parallel tasks
- PEP 3148 – futures – execute computations asynchronously
Leave a Reply